
This second and last episode about the automatic cleanup mechanisms in the Linux kernel covers the concept of classes, macros being used to automatically release resources like mutexes, and the ongoing work to increase its coverage. If you know nothing or very little about the cleanup compiler attribute and how it works, please take a look at the first episode, and then get back to this one.
The goal is to ensure that even beginners with only basic knowledge of C are not left behind, while also providing useful information for experienced developers who may not be familiar with the topics covered in this article. I have included very basic examples for the beginners, and slightly more advanced mechanisms for the experienced developers. Please pick whatever you find useful for your level, and if you notice anything I could improve to make things clearer, please provide your feedback!
Content:
- 1. Classes in the kernel
- 2. Automatic mutex handling
- 3. Other cleanup macros in the Linux kernel
- 4. Ongoing work
1. Classes in the kernel
Don’t get scared (or too excited), the Linux kernel has not adopted C++. Classes in the Linux kernel are not exactly what you might know from other programming languages: they are built upon the concepts we have seen so far to increase resource management automation.
Think of them as objects that provide a constructor and a destructor. If you know nothing about classes, constructors, and destructors, it does not matter: we are simply going to define a new type (typedef in C) out of an existing one, and create an automatic initializer for new objects of that type (the constructor). The destructor is the function for the automatic cleanup we have already learned. I will use a rather loose terminology throughout this article to make sure that any pure C programmer understands everything at first (or maybe second) glance.
At the moment of writing, classes don’t support fancy features you might know from other programming languages, and they might never do, so keep calm and continue thinking in C terminology.
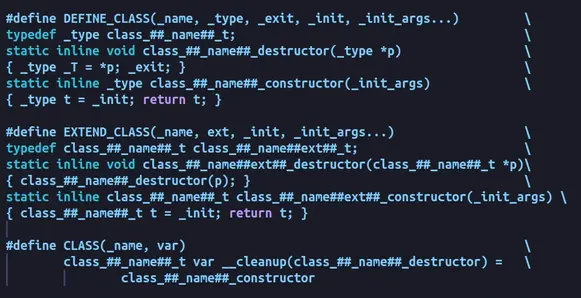
How do we define a class, and how do we declare objects of the class? Once again, the macros defined in include/linux/cleanup.h are the way to go. In particular, we are going to analyze DEFINE_CLASS and CLASS:
// Macro to define classes:
#define DEFINE_CLASS(_name, _type, _exit, _init, _init_args...) \
typedef _type class_##_name##_t; \
static inline void class_##_name##_destructor(_type *p) \
{ _type _T = *p; _exit; } \
static inline _type class_##_name##_constructor(_init_args) \
{ _type t = _init; return t; }
// Macro to declare an object of the class:
#define CLASS(_name, var) \
class_##_name##_t var __cleanup(class_##_name##_destructor) = \
class_##_name##_constructor
Before you give up: the macros are easier than they look, and in the end they do nothing more than defining a class and instantiating objects of that class. Not only that, you will find the following trivial example in the same header file, which I am going to digest for you:
DEFINE_CLASS(fdget, struct fd, fdput(_T), fdget(fd), int fd)
CLASS(fdget, f)(fd);
if (!f.file)
return -EBADF;
// use 'f' without concern
This example shows how to use a class to automatically manage file references, but it could be any other resource you would like to get and then release, like a mutex (more about it in the next section). fdget is the class name, struct fd is the type we are going to use for our typedef, _exit is the destructor, _init the constructor, and _init_args... the arguments we want to pass to the constructor.
In this case, a class named fdget is defined, which is nothing more than a struct fd (some struct defined somewhere, it doesn’t matter) that calls fdget() with int fd as the argument when an object of the class is created. When the object (variable) goes out of scope, fdput() is automatically called.
If you are still lost, I got you. Let’s expand the CLASS macro based on what was passed to DEFINE_CLASS by simply replacing the parameters in the macro definitions with the ones used for the example:
/* DEFINE_CLASS(fdget, struct fd, fdput(_T), fdget(fd), int fd) expands to: */
// 1. typedef:
typedef struct fd class_fdget_t;
// 2. destructor:
static inline void class_fdget_destructor(struct fd *p) { struct fd _T = *p; fdput(_T); }
// 3. constructor:
static inline struct fd class_fdget_constructor(int fd) { struct fd t = fdget(fd); return t; }
/* CLASS(fdget, f)(fd) expands to: */
class_fdget_t f __cleanup(class_fdget_destructor) = class_fdget_constructor(fd);
// That looks similar to what we saw in the first episode, doesn't it?
// variable declaration + cleanup macro, and some initialization.
We have simply declared an object called f of the fdget class, whose type is class_fdget_t (basically a struct fd with new superpowers), by means of the CLASS macro. We have initialized f with our constructor that received fd as the argument for the initialization.
The fd file reference will be automatically released when f goes out of scope with the mechanism we already know (here the destructor function), so we don’t have to worry about forgetting a call to fdput() every time f goes out of scope.
In principle, you will seldom (if ever) call DEFINE_CLASS yourself. The class definition is only made once, and then all users can simply use CLASS to declare the objects and used them as required.
Still not clear? I am running out of ideas, but I may have one more for total noobs. Let’s rewrite the program from the first episode to include the new macros and hence support classes. Feel free to copy the code and experiment with it:
/* class.c */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct foo {
char *name;
};
static inline void foo_cleaner(struct foo *foo)
{
printf("Bye %s\n", foo->name);
free(foo->name);
free(foo);
}
static inline struct foo *foo_builder(const char *name)
{
struct foo *foo = malloc(sizeof(*foo));
foo->name = strdup(name);
printf("Hello %s\n", foo->name);
return foo;
}
/************** OUR "API" internals **************/
// Macro to define classes:
// 1. typedef
// 2. destructor
// 3. constructor
#define DEFINE_CLASS(_name, _type, _exit, _init, _init_args...) \
typedef _type class_##_name##_t; \
static inline void class_##_name##_destructor(_type *p) \
{ _type _T = *p; _exit; } \
static inline _type class_##_name##_constructor(_init_args) \
{ _type t = _init; return t; }
// Definition of the foo class
DEFINE_CLASS(foo, struct foo *, foo_cleaner(_T), foo_builder(name), const char *name)
// __free() is used in the CLASS macro to set the destructor
#define __free(_name) __attribute ((__cleanup__(_name)))
/******************* OUR "API" *******************/
// Macro to declare an object of the class:
#define CLASS(_name, var) \
class_##_name##_t var __free(class_##_name##_destructor) = \
class_##_name##_constructor
/*************************************************/
int main()
{
CLASS(foo, f)("Javier Carrasco");
printf("Nice to meet you, %s\n", f->name);
return 0;
}
Now let’s compile and run the program. I will use Valgrind to make sure that there are no memory leaks:
$ clang -g -o class class.c
$ valgrind ./class
==8111== Memcheck, a memory error detector
==8111== Copyright (C) 2002-2022, and GNU GPL'd, by Julian Seward et al.
==8111== Using Valgrind-3.21.0 and LibVEX; rerun with -h for copyright info
==8111== Command: ./class
==8111==
Hello Javier Carrasco
Nice to meet you, Javier Carrasco
Bye Javier Carrasco
==8111==
==8111== HEAP SUMMARY:
==8111== in use at exit: 0 bytes in 0 blocks
==8111== total heap usage: 3 allocs, 3 frees, 1,048 bytes allocated
==8111==
==8111== All heap blocks were freed -- no leaks are possible
==8111==
==8111== For lists of detected and suppressed errors, rerun with: -s
==8111== ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
No memory leaks, 0 errors, and we got the expected output. Awesome!
By the way, why did Valgrind find 3 allocs and 3 frees when there are only two calls to malloc() and two calls to free()? I am sure that you can figure it out ![]()
(Leave this your second reading if you are struggling) If you open the cleanup header file, you will find another macro between DEFINE_CLASS and CLASS called EXTEND_CLASS. It is used to get a new class with its own constructor out of an existing class, and at the moment of writing is not used out of cleanup.h. That does not mean that it is dead code, as we will see in the next section, when conditional mutexes are created out of blocking mutexes.
Great, now that we know how classes work in the Linux kernel, let’s see a fairly common case: the mutex class.
2. Automatic mutex handling
Although it may have great potential, you will not find many real cases where DEFINE_CLASS is used in the kernel (there are currently 6 calls outside cleanup.h). Nonetheless, its usage for mutex handling is becoming pretty common in several subsystems, even though the macros are not called like we did in the previous section. Surprise, surprise: there are some more macros in cleanup.h, and the ones we are going to see now are specific for mutexes. Don’t panic, they are simple wrappers around the macros we just saw:
- How do we define a new mutex (from now on, guard) class? With
DEFINE_GUARD:#define DEFINE_GUARD(_name, _type, _lock, _unlock) \ DEFINE_CLASS(_name, _type, if (_T) { _unlock; }, ({ _lock; _T; }), _type _T); \ static inline void * class_##_name##_lock_ptr(class_##_name##_t *_T) \ { return *_T; }Once again, you will seldom define a class for mutexes yourself. There will probably be one already that suits your needs. And if not, you will only have to use
DEFINE_GUARDonce for the required type. - How do we declare a new object of the mutex class? With
guard:#define guard(_name) \ CLASS(_name, __UNIQUE_ID(guard))
As you might have guessed, there is already a class definition for the regular mutex struct mutex (in include/linux/mutex.h). That means that we can simplify the use of that mutex for a given scope with a single line like this: guard(mutex)(&my_mutex);, which will expand to what we know: a variable declaration + cleanup macro, and some initialization. In this case, the initialization is a mutex lock, and the cleanup is a mutex unlock. Exactly what we want.
You will find several examples in the kernel, for example in the IIO subsystem, where I used this mechanism for the hdc3020 and veml6075 drivers. Not releasing a taken mutex is terrible, and not that difficult to forget if the scope has multiple exit points (return, goto). The guard macro is short and simple, it works as expected, and having a reliable mechanism to avoid deadlocks gives peace of mind. By the way, you will find other macros that automate cleanups in that subsystem, because as we will see later, the maintainer is the author of some of them.
Before we move to the next section, I would like to mention another guard macro that you will find in the kernel, and is really nice: scoped_guard. It works like guard, but instead of applying for the current scope, it only applies for the immediate compound statement i.e. the next instruction or instructions within curly brackets:
scoped_guard(mutex)(&my_mutex)
// do something
scoped_guard(mutex)(&my_mutex) {
// do a bunch of things
}
Often you want to release the mutex as soon as the resource is available again, and there is no need to wait until the end of the current scope is reached. There has already been some refactoring to use scoped guards where the regular ones were used. Be wise and use the right tool for the job!
(Leave this for your second reading if you are struggling) DEFINE_COND_GUARD is a wrapper around EXTEND_CLASS to define conditional mutexes, which are out of the scope of this article. In a nutshell, and simplifying things, they return if the lock operation did not work instead of sleeping until the operation is permitted. There is also the scoped_cond_guard macro to work with scoped conditional mutexes, so you have multiple choices. Moreover, some subsystems use their own wrappers for specific tasks they carry out on a regular basis. But once you understand the basic macros, everything else is just syntactic sugar.
It might be worth mentioning that there are some additional macros (DEFINE_LOCK_GUARD_*, you will find them at the end of cleanup.h) to create guards with types for locks that don’t have a type themselves (e.g. RCU, where DEFINE_LOCK_GUARD_0, that receives no type argument, is used for that purpose. See rcupdate.h), or require a pointer to access/manipulate some data for the locking/unlocking (e.g. interrupt flags in spin_lock_irqsave).
3. Other cleanup macros in the Linux kernel
If you liked the scoped_guard we saw in the previous section, you are going to enjoy the following macros. It is fairly common in the Linux kernel that the lifetime of an object (whatever the object is, think of some allocated resources) is given by a refcount (to count references to the object). When that refcount reaches zero, no one needs the object anymore, and it can be released. It is often the case, that an iterator (e.g. a pointer) is used in a loop to iterate over a series of objects, incrementing the object’s refcount as long as it is in use to ensure its availability, and decrementing it at the end of the iteration. That sounds like a good fit for some kind of custom-scoped magic, doesn’t it?
A good example could be the iteration over nodes from a device tree. I have already talked about device trees in other articles like this one, so please check it out if you know absolutely nothing about them. I try to make the explanation generic anyway, so you can keep on reading.
The refcount handling in loops has been automated long time ago by keeping the refcount of the current object greater than zero as long as it is in use, repeating that operation until there are no more objects to iterate over, but there is a trick: that automation only works as long as the end of the loop is reached. But often we don’t want to iterate over all possible nodes, right? We could have found the one we were looking for, or even want to exit after some error occurs.
In those cases, the object’s refcount must be manually decremented to reach its original value before the iteration, and avoid a memory leak by preventing the object’s refcount to ever be zero (e.g. after removing a module). Manual intervention is always dangerous. Actually, I have fixed multiple bugs in such loops while writing this article by just looking for examples, like this one, this one, or this one. Even though a wrong refcount handling does not directly lead to a leak as long as the object stays in use, what will happen with that object in the future is often difficult to control and predict. By now you should be convinced that when used with care, the cleanup attribute is a great addition to the kernel.
The new macros to handle such iterative tasks have the same name as the old ones, plus the _scoped suffix. Their implementation is also similar, and by now you should understand the difference without any explanation from my side. Let’s see for example device_for_each_child_node() and device_for_each_child_node_scoped(), which was recently added by Jonathan Cameron (IIO maintainer):
#define device_for_each_child_node(dev, child) \
for (child = device_get_next_child_node(dev, NULL); child; \
child = device_get_next_child_node(dev, child))
#define device_for_each_child_node_scoped(dev, child) \
for (struct fwnode_handle *child __free(fwnode_handle) = \
device_get_next_child_node(dev, NULL); \
child; child = device_get_next_child_node(dev, child))
Exactly, whatever is going on within that loop, the __free() macro is the key to automatically release that fwnode_handle child after every iteration, no matter what that child is. As I said, it has something to do with inner nodes of some device from a device tree, but the important thing is to understand the pattern. Of course, there must be a DEFINE_FREE for the fwnode_handle to define the cleanup function, but that is also something we have already learned in the first episode.
Let’s see how you can easily mess up with the non-scoped version of these macros, and how easy the fixes with the scoped macros can be (not always, though… case by case!). In this case, I used for_each_child_node_scoped() to fix this memory leak in the sun50i cpufreq driver:
static bool dt_has_supported_hw(void)
{
bool has_opp_supported_hw = false;
struct device *cpu_dev;
cpu_dev = get_cpu_device(0);
if (!cpu_dev)
return false;
struct device_node *np __free(device_node) =
dev_pm_opp_of_get_opp_desc_node(cpu_dev);
if (!np)
return false;
for_each_child_of_node(np, opp) {
if (of_find_property(opp, "opp-supported-hw", NULL)) {
has_opp_supported_hw = true;
break; // early exit with no fwnode_handle_put(opp) to decrement refcount!
}
}
return has_opp_supported_hw;
}
Attach _scoped to for_each_child_of_node, and the bug is fixed. And if another early exit is added in the future, we are still safe. Is that not great?
4. Ongoing work
Even though the scoped versions of a number of such macros are already available in the mainline kernel, there are still others that only have the non-scoped variant. They are waiting for a use case where it makes sense (e.g. fixing a bug where manual release is missing), and therefore the number of members of the _scoped family will probably grow in the next months/years. Similarly, there are many objects that don’t have their own __free() or an associated class, and I bet that some of them could profit from that as well.
I sent myself this patch (still being discussed, mainly for other reasons than the cleanup mechanism itself) a few days ago to fix a bug in the hwmon ltc2992 driver where the current fwnode_for_each_available_child_node is not correctly used. The people who were involved in the design and implementation of the automatic cleanup mechanisms paved the path, and now we can profit from it to add new use cases like this one. Props to them!
The Linux Kernel Mentorship Program from the Linux Foundation is (among many others) also pushing the use of the __free() macro forward by refactoring existing code where error paths increase the risk of missing a memory deallocator. This task was proposed by Julia Lawall during a mentoring session about Coccinelle, and several patches have already been accepted. I must admit that some subsystems were more enthusiastic than others, but in general they are making their way to the kernel.
To be honest, I understand why some maintainers are pushing back. I refactored some easy code myself to be able to review my mentees’ work, and since then I restricted myself to adding the feature to new code or where it fixes real bugs and the improvement is undeniable. Some refactoring where a bunch of goto jumps vanishes is in my opinion a good patch to apply, but we have already seen that there are many things to consider to avoid regressions. A few maintainers still don’t feel comfortable with the auto cleanup stuff (some were completely unaware of it), and they could miss some potential regressions when reviewing patches. If you want to do some refactoring anyway, please be very careful, and make sure you understand the internals. I hope my articles helped a bit!
Apart from the ongoing work I mentioned, I suppose there is much more being discussed in multiple mailing lists. I will let you investigate on your own. Maybe you are even working on some extensions I don’t know… I would love to hear about it!
Hopefully the ongoing work will continue increasing code quality and above all, delivering a better kernel to the end user.